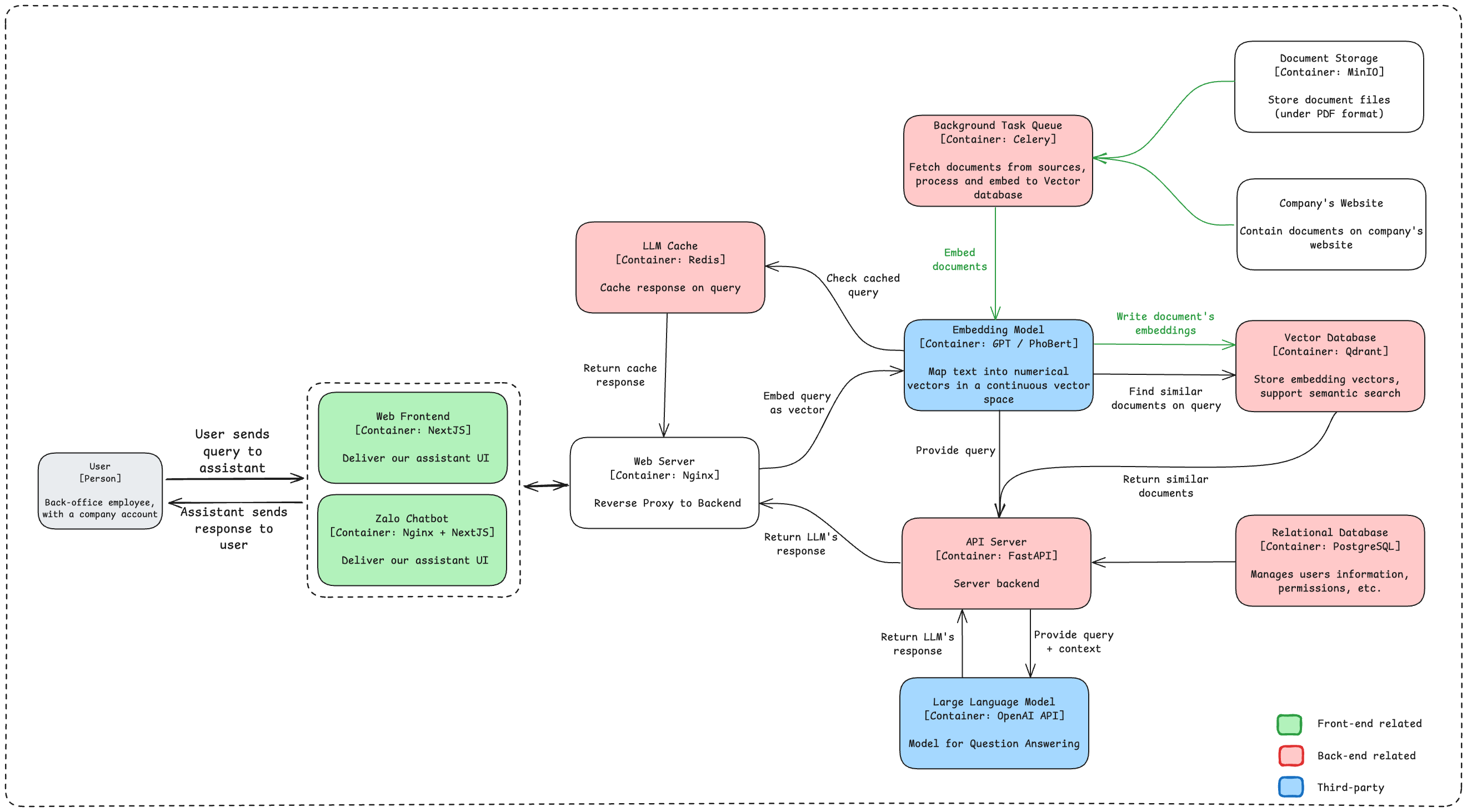
Hardware Resourcing

Recommended CPU / RAM / Disk to run EzHR Chatbot.
Running Locally (Docker Compose)
If you are running your app locally using Docker, it is advised to allocate at least 4 vCPU cores and 4 GB of RAM to Docker, with 10 GB storage being the preferred amount. You can manage these settings within the Resources section of Docker Desktop.
Single Cloud Instance
| Component | Minimum Requirement | Recommended |
|---|---|---|
| CPU | 2 vCPU cores | 4 vCPU cores |
| Memory (RAM) | 4 GB | 8 GB |
| Disk | 10 GB + 2.5x indexed documents | 50–100 GB (extra space) |
| GPU | Not required | Not required |
1. Processor (CPU):
- Requirement: At least 2 vCPU cores.
- Recommended: 4 vCPU cores for smoother performance.
- Reason:
- Supports concurrent execution of multiple Docker containers.
- Handles CPU-bound processes such as the API server, Redis cache, Nginx reverse proxy, and embedding model.
- Supported CPU architectures:
- 64-bit system:
- x86_64/amd64
- AArch64/arm64
- 32-bit system: Not supported
- 64-bit system:
2. Memory (RAM):
- Requirement: At least 4 GB of RAM.
- Recommended: 8 GB of RAM for optimal performance.
- Reason:
- Provides sufficient memory for:
- Running the embedding model and the vector database.
- Storing cached results in Redis for improved query response times.
- Provides sufficient memory for:
3. Storage
- Requirement: Minimum of 10 GB plus roughly 2.5 times the size of the indexed documents.
- Recommended: Extra disk space for flexibility, such as 50–100 GB, as storage is generally inexpensive.
- Reason:
- Document Storage (MinIO): Holds company documents (e.g., PDFs).
- Vector Database (Qdrant): Stores document embeddings, which scale with the number and size of indexed documents.
- Docker images and container logs require additional space.
Qdrant Consideration
For persistent storage, Qdrant requires block-level access to storage devices with a POSIX-compatible file system. Network systems such as iSCSI that provide block-level access are also acceptable.
Qdrant won't work with Network file systems such as NFS, or Object storage systems such as S3.
If you offload vectors to a local disk, we recommend you use a solid-state (SSD or NVMe) drive.
4. GPU
- Requirement: Not Required.
5. Networking
These following ports are used by services:
1433: For communcating with SQL Server asdatabase6379: For communicating with Redis ascache6333: For communicating with Qdrant asindexvia HTTP API, for the Monitoring health and metrics endpoints6334: For communicating with Qdrant via gRPC9000: For access web interface of MinIO asobject-storage9001: For communicating with MinIO API asobject-storage5000: For communicating with Backend asapi-server3000: For frontend - web interface
Details on Resource Consumsion
| Component | CPU | Memory | Notes |
|---|---|---|---|
api-server | 1 CPU | 1 GB | Handles query processing and LLM integration. |
background | 1 CPU | 256 MB | For document embedding and background tasks. |
database (SQL) | 500m CPU | 2 GB | Can share existing SQL resources to save costs. |
qdrant | 1 CPU | 256 MB | Scales with document volume; higher recommended. |
nginx + frontend | 250m CPU | 512 MB | For serving the UI and reverse proxy setup. |
Scaling Considerations
For heavier workloads or larger datasets, consider:
- Expanding CPU cores (e.g., 6–8 cores) to handle higher query throughput.
- Increasing memory to 16 GB for processing larger datasets or running concurrent queries.
- Reserving additional disk space to accommodate future growth in indexed documents.
Kubernetes or AWS ECS
For more fine-grained control and efficient scaling, you can deploy each component to its own dedicated resources in a Kubernetes or AWS ECS environment.
NOTE: We are not currently support deployment on kubernetes. These numbers should be reference-only.
| Component | CPU | Memory | Notes |
|---|---|---|---|
api-server | 1 CPU | 1 GB | Handles query processing and LLM integration. |
background | 1 CPU | 256 MB | For document embedding and background tasks. |
database (SQL) | 500m CPU | 2 GB | Can share existing SQL resources to save costs. |
qdrant | 1 CPU | 256 MB | Scales with document volume; higher recommended. |
nginx + frontend | 250m CPU | 512 MB | For serving the UI and reverse proxy setup. |
General guides:
-
Component Separation: Deploy each major component (
api-server,background,database,qdrant,nginx,frontend) as individual Kubernetes Deployments or StatefulSets for easier scaling and management. -
Resource Requests and Limits: Use Kubernetes resource requests and limits to ensure fair CPU and memory allocation:
resources:
requests:
memory: "256Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "1" -
Persistent Storage: Use Persistent Volume Claims (PVCs) for storage-heavy components like:
- Qdrant: Store vector embeddings persistently.
- MinIO: For document storage.
- Example:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: qdrant-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
-
Load Balancer: Use an Ingress Controller (e.g., NGINX) to manage external traffic to the
frontendandapi-server.- Example:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: app-ingress
spec:
rules:
- host: app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend-service
port:
number: 80
- Example:
-
Autoscaling: Use Horizontal Pod Autoscaler (HPA) for scaling critical components based on CPU or memory usage:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80 -
Configuration Management: Store sensitive information (API keys, database credentials) in Secrets and other configuration in ConfigMaps:
apiVersion: v1
kind: Secret
metadata:
name: api-secrets
type: Opaque
data:
OPENAI_API_KEY: <base64_encoded_key> -
Monitoring and Logging: Use tools like Prometheus, Grafana, and Fluentd to monitor resource usage and collect logs for debugging.
-
External Dependencies: If using external LLM services (e.g., OpenAI API), ensure network egress rules and API rate limits are configured properly.
-
Helm or Kustomize: Use Helm charts or Kustomize to template and manage complex Kubernetes configurations for better reusability and versioning.